One the my biggest data-quality frustrations with CMS data is the non-standardization of key fields, which prevents effective aggregation and analysis.
The best example of this is the “payer” and “filer” fields. The payor fields Applicable_Manufacturer_or_Applicable_GPO_Making_Payment_ID and Applicable_Manufacturer_or_Applicable_GPO_Making_Payment_Nameidentify into the pharmaceutical companies making the payments. Although the ‘ID’ field is standardized for the most part, there are 16 companies that have 2 IDs, each – I’m sure what the reason is behind these anomalies.
The ‘Name’ field is not standardized at all. Since this is a free-text field, there are substantial differences in how a name of a company is reported. The primary difference between naming versions is capitalization differences and the regular interchange of business entity designations forms (e.g. “INC” <-> “INCORPORATED”).
However, all of these challenges can be dispelled fairly easily through routine data-cleaning. The true limitation with payer-company data is that there are no CMS procedural reporting controls in place to prevent reporting at the subsidiary level.
This creates a problem when you want to profile payment behaviour at the parent-company level. An illustrative example is a company like Pfizer Inc., which has a expansive network of subsidiaries. If you want to understand how Pfizer markets its products at the organizational level, you may try to aggregate payment activity over companies that have the term “Pfizer” in their name.
Unfortunately, this is a terrible strategy. There is no way for you associate payments made by subsidiaries like “WARNERLAMBERT CO LLC”, “PARKEDALE PHARMACEUTICALS INC”, and “RINAT NEUROSCIENCE CORP” to Pfizer. Consequently, you get decent amount of information loss and any models you create don’t accurately reflect total organizational behaviour.
The best work around is drawing connections between the payer fields and the filer Submitting_Applicable_Manufacturer_or_Applicable_GPO_Name field. Once this free-text field is cleaned and standardized, it’s fairly easy to trace-back subsidiary-parent relationships native to the CMS data. Most companies will have either one or two filers. The rationale is that sometimes the subsidiary will file records on it’s own behalf, and sometimes it’s parent will take the lead. Using this framework, you can map relationships fairly simply:
- If the company has only one filer, then the payer company is the parent.
- If the company has two filers, then the parent is the filer whose name is different from the payer company name.
A small number of payer companies have more than 2 filers, but it’s something that can be easily cleaned up with a little manual intervention and a few google searches.
In the end, this is what the native CMS parent-subsidiary relationships look like …
The plot shows number of identified subsidiaries identified for each parent company based on native CMS payer-filer relationships. The image is fairly long so you’ll have to click on it, then click “view full size” in the bottom right-hand corner to get a proper view.

So – the big question: Why does this even matter? Well, as previously mentioned, you’ll get a decent amount of information-loss since subsidiary payment behaviour can be drastically different from the parent organization’s. Thus, your models lose inaccuracy if you fail to capture all relationships. A good example of this is Boehringer Ingelheim, which reported payments under 40 different subsidiaries. Most subsidaries made payments to between 1 and 10 doctors, but 4 had substantial activity.
The following plots compare payment behaviour between the parent and it’s subsidiaries. Note, subsidiaries that made payments to less than 50 doctors were excluded. Payment data was aggregated at the doctor level for all activities between 2013 and 2016. A sample size of 2000 doctors was used when available, otherwise 75% of all doctors paid by the subsidiary were sampled. As with the previous post, data is plotted on a natural-log scale and natural-logs of sums were used to compute corresponding gamma-distribution.
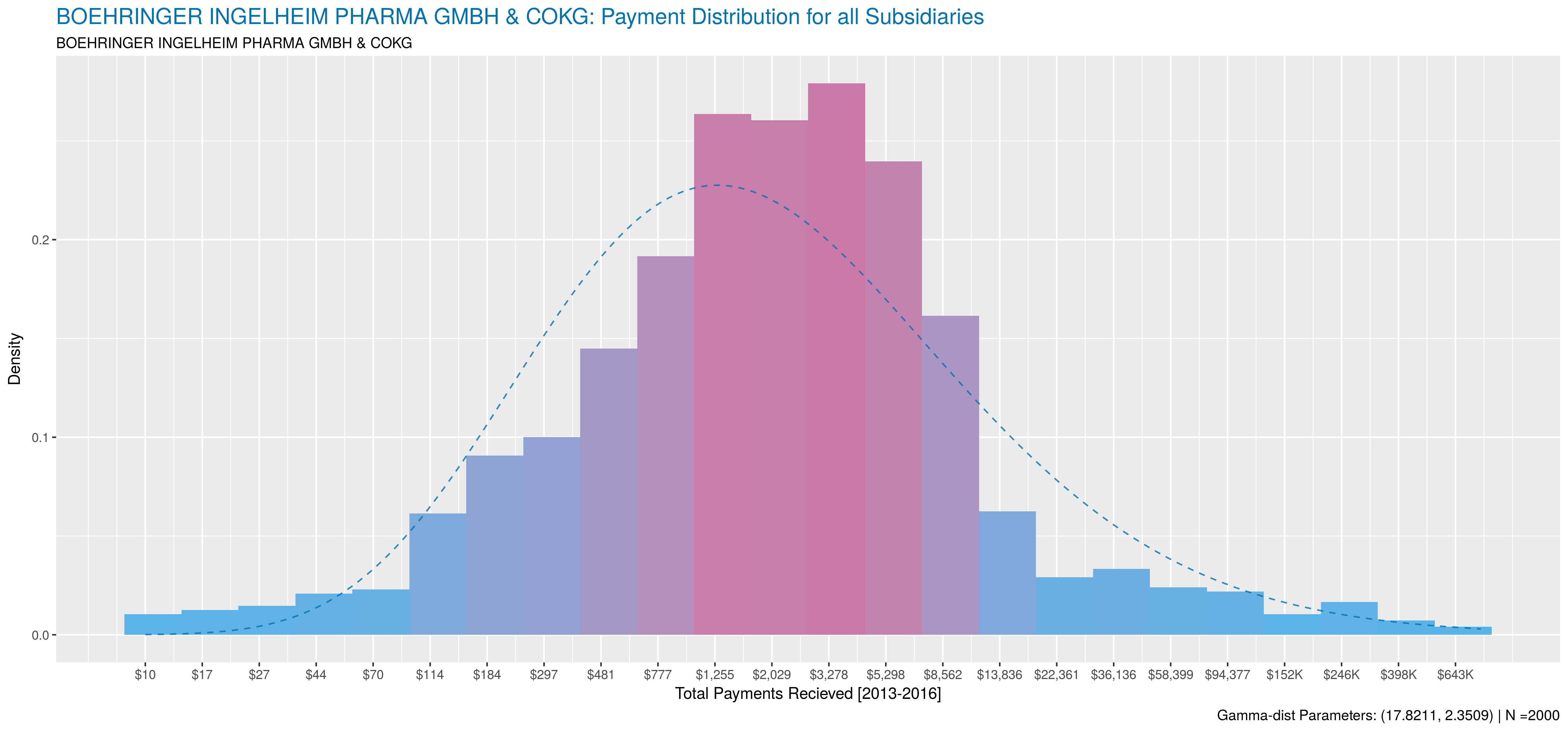

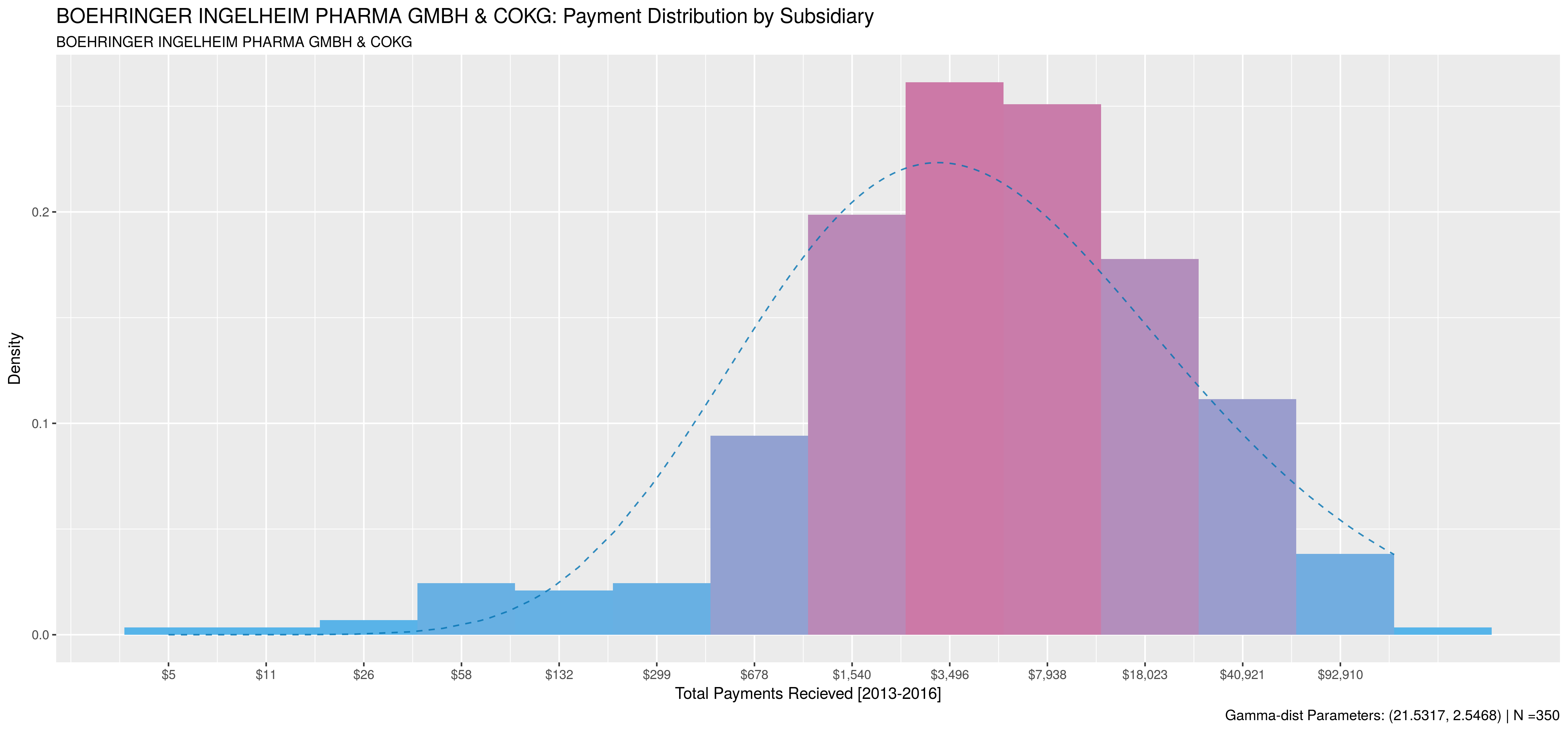
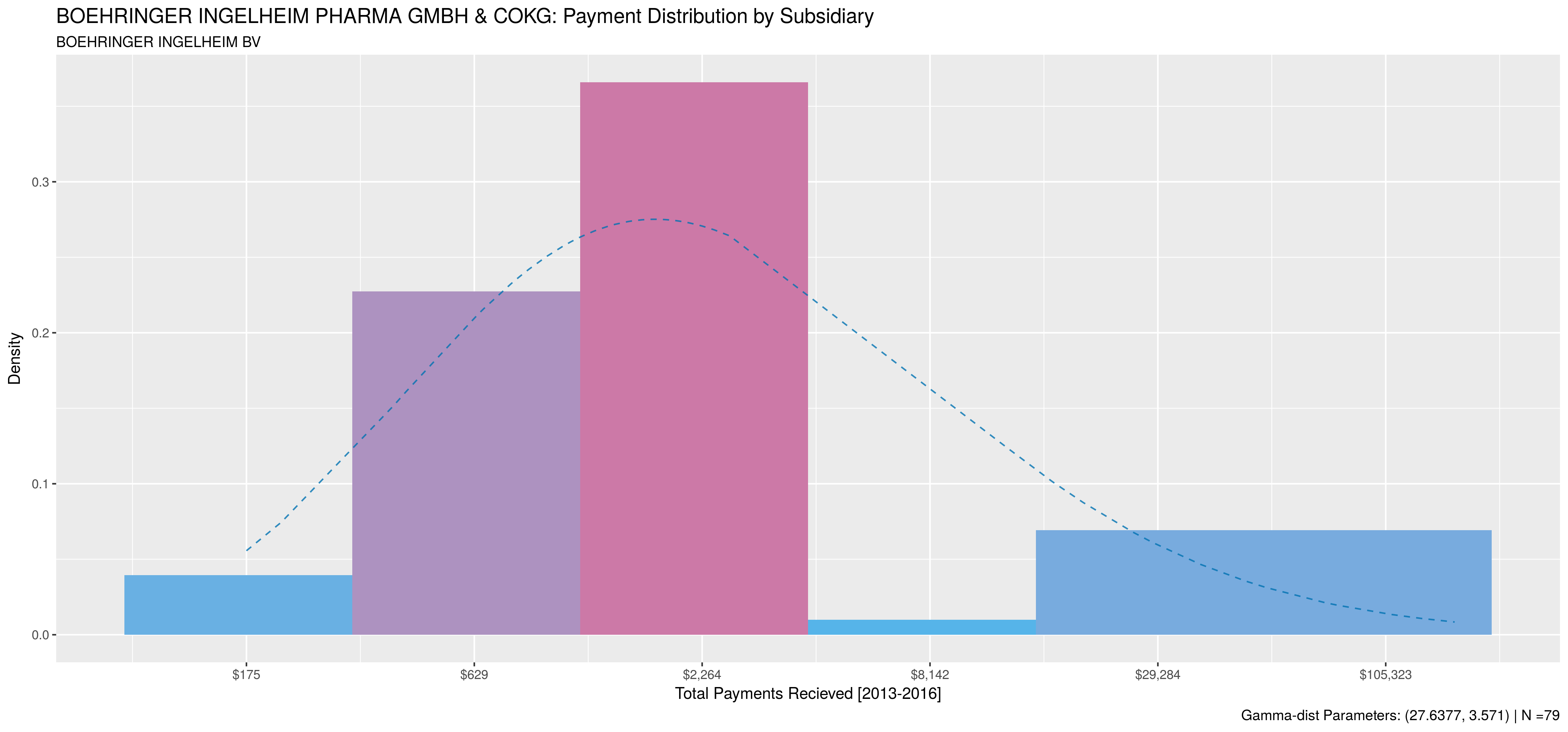
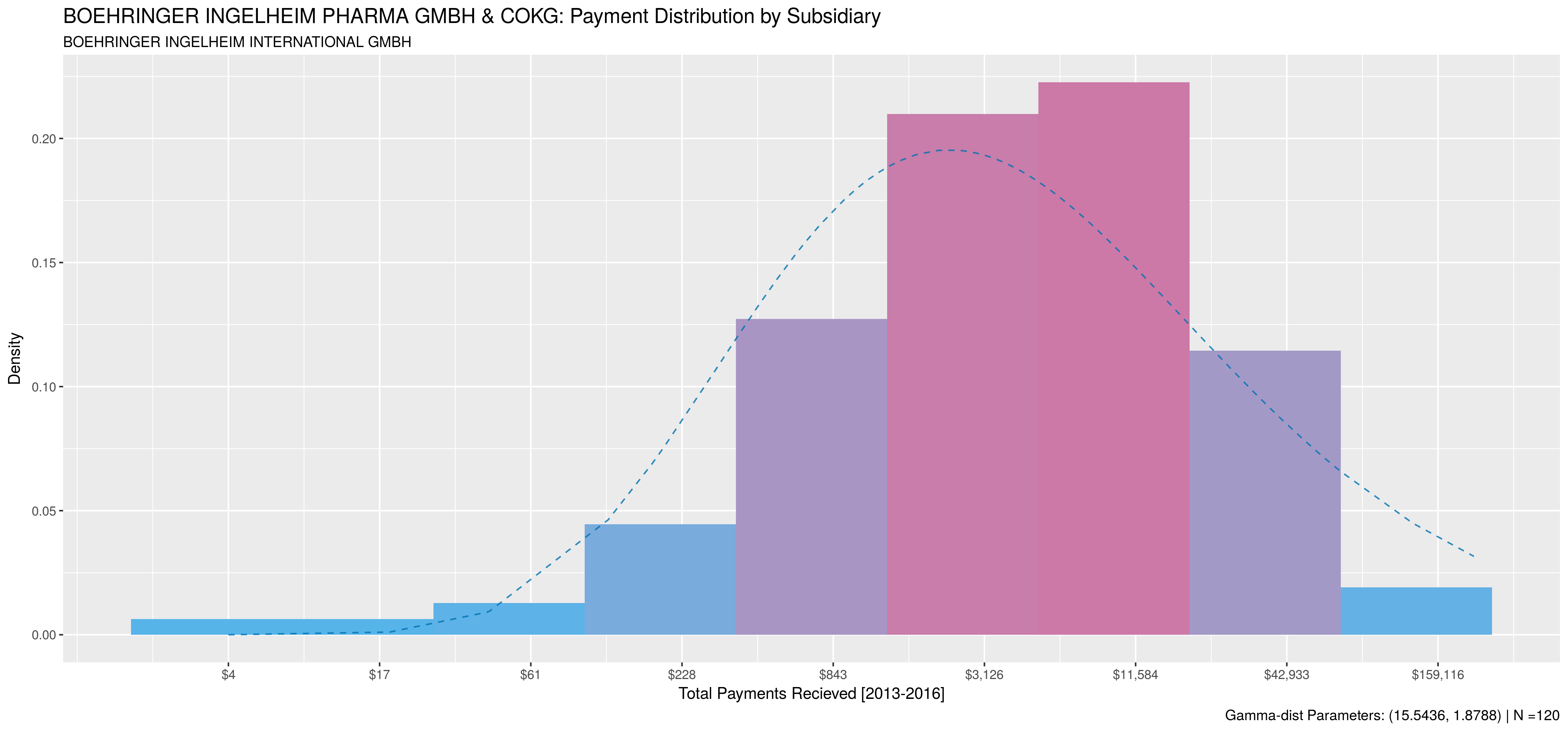
So, as you can see, the parent and each of its subsidiaries involved in marketing activities all have extremely different payment behaviours.
If you are working with the same CMS data and are interested in utilizing my mapped relationships, you can use this file: CMS_NativeParentRelationships
Next question, can we take relationship-mapping further?
You betch’ya! The Sunshine Foundation sponsored the development of the CORPwatch Project, which performs routine crawls of the SEC Edgar Filing database to extract subsidiary listings from quarterly filed 10-K reports.
The major limitation is that it can only provide subsidiary information for companies publicly traded in the USA, therefore you have to rely on CMS native data relationships for subsidiaries of Takeda Pharmaceuticals and other foreign-listed corporations.
Have I completed mapping these higher-level relationships? — Yes.
Can you see payment behaviour plots at the organizational level for all parent companies? — Yes, but **drum-roll** — that’s for the next post.
In the meantime, how about an introduction to what grad-school feels like when you’re trying to also juggle a start-up & a large data project:

[…] reiterate the point of my previous post, parent-subsidiary mapping is essential for accurate marketing data analysis. Genentech is reported […]
LikeLike