I’m finally getting to a point where I can start exploring CMS Open Payments data after a couple months of on-and-off tying in complementary datasets.
Spoiler: There’s probably going to be a decent amount of posts following this one on pharmaceutical marketing practices.
I’m starting things off with a series of visualizations of how payments are spread across the various types of activities.
In short, doctors may receive payment or other compensation for presenting a pharma product at a conference, sitting down for dinner with a pharma rep, or another activities.
So why start here? Well, because my biggest irk is that neither CMS nor ProPublica offer good contextual details when evaluating the payments a doctor has received for promotional activities.
Case in point, CMS will show me the doctor’s position relative to the national average ~ but what does that tell me as a patient?
Absolutely nothing. There’s huge disparities of what is normal and abnormal depending on the promoted pharmaceutical product, the doctor’s academic ranking, the doctor’s specialty, the size of the pharma co, and geography (e.g. Asprin in Birmingham v. Solvandi in NYC). One of the biggest drivers of what is normal, is the type and frequency of payments.
Here, we’ll explore the variation in payment activities by promotional activity type.
Each payment’s corresponding activity type is recorded in the standardized "Nature_of_Payment_or_Transfer_of_Value" field.
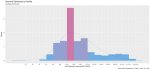
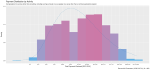
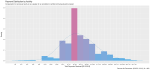
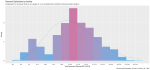
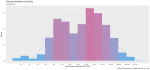
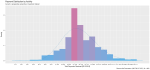
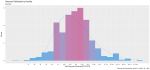
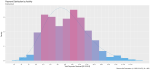
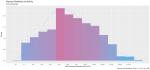
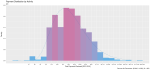
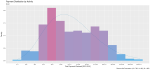
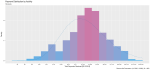
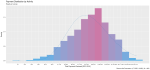
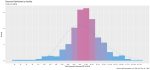
I took a random sample of 1,000 doctors that received compensation for each of the corresponding activity types, aggregated their corresponding payments between 2013 and 2016 and plotted their distribution on a natural-log scale to compensate of the wide range in payment sums.
Finally, I included a gamma distribution function for each activity distribution. I applied the gamma form because I assumed that most payment distributions would skew heavily to the left, with the majority of doctors receiving lower-value payments.
This wasn’t always the case; The bi-modal distribution for consulting payments is interesting.
These visualizations don’t account for factors like geography, product-type, size of the paying firm, etc. — but never fear, just give me a little time.
Code:
# Start-up ----
rm(list = ls()); gc()
setwd("/home/rstudio/Dropbox/_Atlas-Rsync")
# Import Libararies
library(ggplot2)
library(plyr)
library(MASS)
library(stringr)
# Import Data
opdat = readRDS("Payment Data/GNRL_PGYR1316_US_PHYS.rds") # Primary Payments Table
# Generate Key Refrence Objects
activities = levels(opdat$Nature_of_Payment_or_Transfer_of_Value)
activities = activities[c(1:13,15)] # Exlude "teaching hospital" space payments
# Define Functions ----
scotts = function(x){
# Scott's normal reference rule calculation
n = length(x)
std = sd(x)
bw = (3.5*std)/n^(1/3)
return(round(bw, 2))
}
# Generate Plots ----
options(warn = -1) # Suppress warnings generated by ggsave and fitdistr
for(i in 1:length(activities)){
drpop = unique(opdat$Physician_Profile_ID[opdat$Nature_of_Payment_or_Transfer_of_Value == activities[i]])
ndr = ifelse(length(drpop) > 1000, 1000, round(length(drpop)*.75)) # Number of doctors to same for each activity type
drsmpl= drpop[sample(seq(1:length(drpop)), size = ndr, replace = FALSE)]
sdat = opdat[(opdat$Physician_Profile_ID %in% drsmpl) & (opdat$Nature_of_Payment_or_Transfer_of_Value == activities[i]),
c("Physician_Profile_ID","Total_Amount_of_Payment_USDollars")]
sdat.agg = aggregate.data.frame(x = sdat, by = list(sdat$Physician_Profile_ID), FUN = sum)
sdat.agg$Total_Amount_of_Payment_USDollars = log(sdat.agg$Total_Amount_of_Payment_USDollars)
ndr = dim(sdat.agg)[1] # Number of datapoints
p.bw = scotts(sdat.agg$Total_Amount_of_Payment_USDollars) # Calculate bin-width based on Scott's Rule
# Calculate break-points and form Labels
p.breaks = seq(min(sdat.agg$Total_Amount_of_Payment_USDollars[sdat.agg$Total_Amount_of_Payment_USDollars > 0]),
max(sdat.agg$Total_Amount_of_Payment_USDollars), by = p.bw)
p.labels = paste("$", prettyNum(round(exp(p.breaks), 0), big.mark = ","), sep = "")
# Define other plot traits
p.title = list("Payment Distribution by Activity",
element_text(hjust = 0, size = 14))
p.subtitle = list(activities[i],
element_text(size = 10))
p.name = paste("Plots and Analyses/Payment Behavior by Activity/",
str_pad(as.character(i), width = 2, side = "left", pad = "0"),"_",
gsub("\\s","_",substr(activities[i], 1, 20)),".png",sep = "")
# Get gamma-distribution fit
fit = fitdistr(sdat.agg$Total_Amount_of_Payment_USDollars[sdat.agg$Total_Amount_of_Payment_USDollars > 0], densfun = "gamma")
# Make plot
ggplot(data = sdat.agg, aes(n = ndr, bw = p.bw)) +
geom_histogram(binwidth = p.bw,
aes(sdat.agg$Total_Amount_of_Payment_USDollars,
y = (..count..)/(n*bw), fill = ..count..)) +
scale_x_continuous(name = "Total Payments Recieved [2013-2016]",
breaks = p.breaks, labels = p.labels) +
scale_fill_gradient("count",low = "#56B4E9", high = "#CC79A7") +
ylab("Density") +
labs(title = p.title[[1]],
subtitle = p.subtitle[[1]],
caption = paste("Gamma-dist Parameters: ", "(", as.character(round(fit[[1]][1], 4)), ", ",
as.character(round(fit[[1]][2],4)),")", " | N =", as.character(ndr) ,sep = "")) +
theme(plot.title = p.title[[2]], plot.subtitle = p.subtitle[[2]],
legend.position = "none") +
geom_line(aes(x = sdat.agg$Total_Amount_of_Payment_USDollars,
y = dgamma(sdat.agg$Total_Amount_of_Payment_USDollars, shape = fit[[1]][1], rate = fit[[1]][2])),
color = "#0072B2", size = .5, alpha = .8, linetype = 2)
# Save Plot
ggsave(filename = p.name, plot = last_plot(), width = 15, height = 7)
graphics.off()
}
Congrats, you made it to the end of this post.
More good news, a Maks Korzh album dropped the other day; I don’t know about you, but I’m pretty ecstatic.
(English subs and dope beats included)

[…] noted in my OPD#1 post, D2D marketing can take many forms and the typical value derived by physicians can vary […]
LikeLike
[…] of these three (3) transaction-types have unique distributions, as visualized and examined in a previous post. A cursory review of Subsys transactions found that payments were filed almost exclusive under the […]
LikeLike